快速开始
快速开始指南的目的是把这个项目快速的运行起来。
Open-LLM-VTuber 是一个由��非常多部分组成的项目,并且有非常多的可选配置项。你可以用自己喜欢的大语言模型,配置不同的大语言模型推理后端,修改语音识别引擎 (ASR),改变 AI 的声音 (TTS),改变 AI 的外貌 (Live2D),改变 AI 的人格等等。
本指南着重于用预设选项 (配置起来最简单的选项),让你把东西跑起来。
你可以在完成本指南后,参考用户指南相关的部分来做更深入的配置。
自动部署后端
还没写完 👻
旧版的自动安装脚本应该不能运行了,所以需要更新。
在此之前,先手动部署吧。
手动部署后端
(#开发版)
目前的后端部署属于开发版,v1.0.0 正式发布之前会优化部署过程并修改文档。
标记为 (#开发版) 的部分,是完整打包流程构建之前的文档,在 v1.0.0 发布之前要改掉。
开始部署之前:
安装 ffmpeg
非常重要,没有 ffmpeg 在播放音频时可能会遇到 "找不到音频文件" 的错误!
- Windows 用户,在命令行中运行
winget install ffmpeg安装 - macOS 用户,可以用 brew 包管理器用
brew install ffmpeg安装 - Linux 用户直接用系统包管理器安装,你知道我在说什么。
Nvidia 显卡用户,检查 Cuda
CUDA 和 N 卡驱动部分需要补充
准备虚拟环境
自 v1.0.0 版本开始,这个项目开始使用 uv作为依赖和项目管理工具。
如果你不熟悉 conda 或是 venv,我推荐你跟着我们一起使用 uv。
如果你懂 python 的依赖,可以看一下 uv 的命令指南 熟悉一下 (毕竟这玩意儿比较新)。
如果你坚持使用 conda 或是 venv (或是其他虚拟环境的工具),这个项目依旧可以使用 conda 或是 venv 来安装,后面会提到使用 pip 来安装项目依赖的方式。
安装 uv
可以参考 uv 官方安装文档。安装 uv 的方式有很多,包括 pip, winget, brew 等等。不过如果你看不太懂,下面是我推荐的安装方式。
Windows
- 在命令行里执行
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"来安装 uv - 如果上面这个命令行不通,我们可以试试 winget。试试在命令行运行这个命令
winget install --id=astral-sh.uv -e
macOS & Linux
- 命令行运行
curl -LsSf https://astral.sh/uv/install.sh | sh
开始部署
下载项目后端 (#开发版)
获取 superb-refactoring 开发版本 (#开发版)
一般来说,在正式发布后,我会把最新的压缩包放在 release 页面。
不过我们 v1.0.0 还没正式发布,就先来 git clone 一下吧。
注意,国内用户可能需要开启代理或是使用 github 镜像源。
首先确保你的电脑上有 git
git -v
接着来克隆项目仓库。
git clone https://github.com/t41372/Open-LLM-VTuber
由于现在主分支还在 v0.5.2 版本,我们要切换到 v1.0.0 版本的工作分支。
先进入 Open LLM VTuber 项目目录
cd Open-LLM-VTuber/
接着切换到 superb-refactoring 重构分支
git switch superb-refactoring
现在你已经在 v1.0.0 的开发分支上啦!
自 v1.0.0 开始,前端代码被拆分到了单独的仓库去,我们搭建了一个构建流程,并用 git submodule 链接到了项目主仓库当中的 frontend目录。
不过用 git submodule 链接的东西不会自动出现在目录下,我们要手动获取一下。
运行下面命令来从前端构建仓库中获取前端网页代码。
git submodule update --init --recursive
创建虚拟环境
我们将使用 uv 创建虚拟环境 来管理项目的依赖。
首先确保你的 uv 安装好了。
uv --version
你应该会看到类似这样的东西
uv 0.5.7 (3ca155ddd 2024-12-06)
这样就代表你 uv 安装好了。
接着我们来安装项目的依赖。
在项目目录下,运行:
uv sync
这个命令会在项目目录下创建一个 .venv 虚拟环境,并准备好合适的 Python 版本。
接下来,我们要配置 LLM 大语言模型。如果现在直接运行项目后端,会在对话时出现 Error calling chat endpoint 之类的错误。
配置 conf.yaml 文件
这个项目所有的配置项,包括 大语言模型 (LLM),语音识别 (ASR),语音合成 (TTS) 以及更多配置,都放在 conf.yaml 文件中。
你可以用文本编辑器,比如 VSCode,zed,vim,或是你的IDE 来开启这个配置文件。如果你用程序员喜欢的 IDE 或是文本编辑器开启 .yaml 文件的话,开启时会有代码高亮,对眼睛比较好。我个人推荐使用 VSCode 开启 conf.yaml,但你随意。
如果你是中文使用者,你可以把 conf.yaml 的内容都删掉,然后把 conf.CN.yaml 里的内容贴到 conf.yaml 中。 conf.CN.yaml 提供了更适合中文宝宝体质的预设选项,同时,所有注释都翻译成了中文。
预设的配置文件中提供了一些不太需要配置的选项,但大语言模型的推理后端,我们需要配置。
配置大语言模型 (Ollama)
这里提供一个基于 Ollama 的,最基本的大语言模型配置。
其他选项,比如使用 OpenAI 格式的 LLM API,智谱,DeepSeek,Claude,OpenAI,Gemini 等等,可以参考大语言模型配置
一些 ollama 的平替包括 vllm (难度较高),lm studio (非常容易)。 这个项目也支持 (用llama.cpp) 直接运行 .gguf 格式的模型文件。请参考 大语言模型配置 的 llama.cpp 部分。
安装 Ollama
Ollama 是一个跨平台的 LLM 推理工具,你可以使用 Ollama 来下载,运行大语言模型。
前往 Ollama 官网 安装 Ollama。
安装完之后,运行下面命令来检查安装是否成功。
ollama --version
运行后应该会出现长得像这样的东西
ollama version is 0.5.4
如果出现类似 找不到 ollama 命令 之类的东西,说明你没装好。
如果你一直搞不定,你可以不用 Ollama。可以参考 大语言模型配置 看看其他选项。
用 Ollama 下载大语言模型
前往 Ollama 官网的模型页面看看有没有你喜欢的模型。
对于模型参数量,请量力而为。如果模型文件大于你的显存大小,会炸显存,速度会慢的不行。模型越大,对话延迟也越大。 当 Ollama 炸显存的时候,模型会自�己流到普通内存去并使用 CPU 推理。这非常慢。 如果模型慢的不行,就换个参数量小一些的模型。
我们以 qwen2.5 7b 模型为例子。
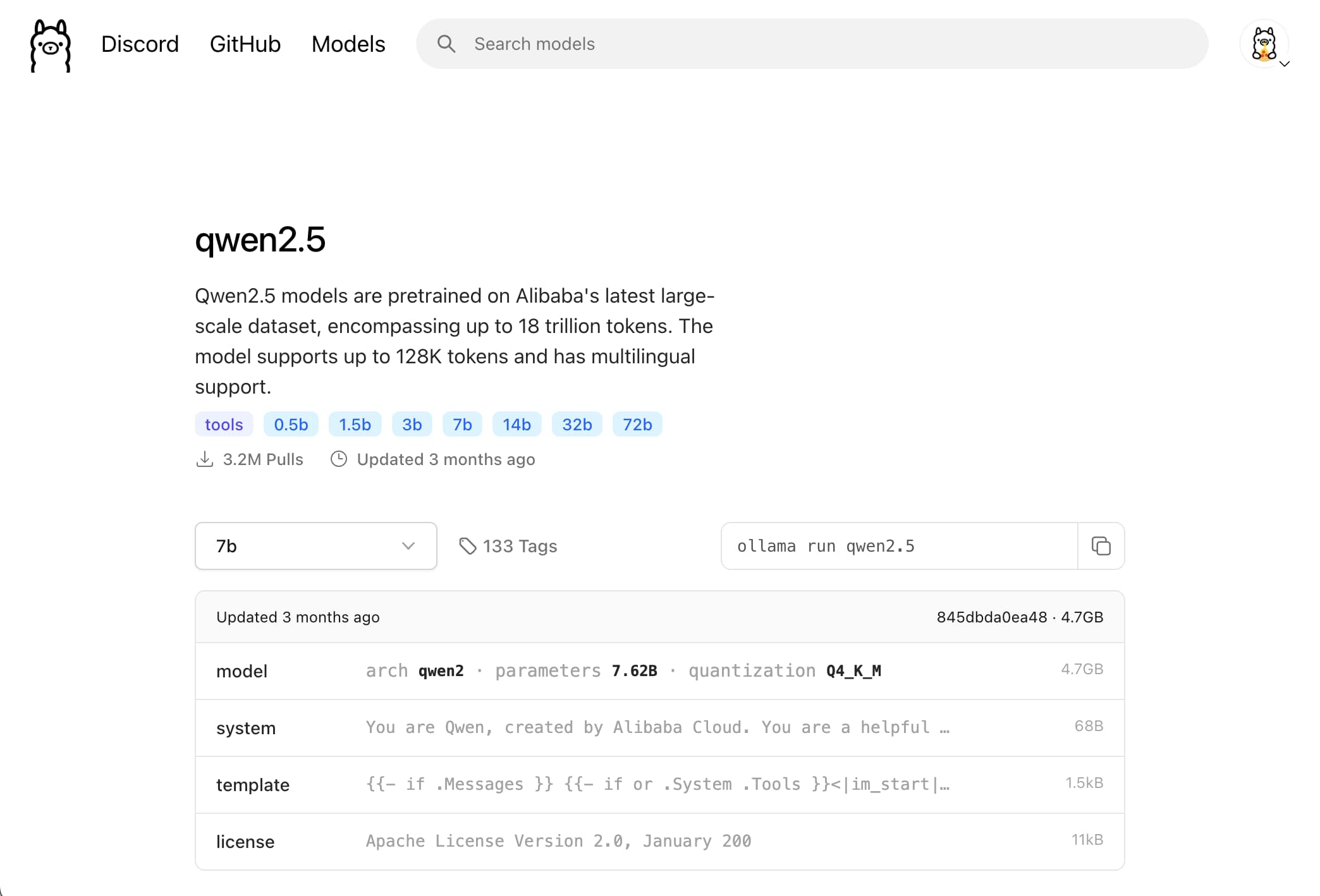
可以在右侧看到模型的大小是 4.7GB。你的显存最好比这个数字大,否则去选个小一些的模型。
我们可以看到右上角有个 ollama run qwen2.5 的命令。只要在命令行运行这个命令,就可以直接下载 + 运行这个模型。
所以,在命令行中运行 ollama run qwen2.5
下载完成之后,你就可以直接跟 qwen2.5 对话了。不过我们可以先退出 (Ctrl + d 退出聊天界面)。
运行 ollama list 看看本地现在都有哪些模型。
➜ ~ ollama list
NAME ID SIZE MODIFIED
qwen2.5:latest 845dbda0ea48 4.7 GB 2 minutes ago
你会注意到这里出现了一个模型。这样就好了。
在 Open-LLM-VTuber 中使用这个模型
请用某种文本编辑器开启 conf.yaml。
找到 basic_memory_agent 选项下的 llm_provider,把右侧的值改成 ollama_llm。这里会将预设的 Agent 所使用的 LLM 后端改成 Ollama。
接下来,我们配置一下 Ollama 的对接设置。
往下走走,找到 llm_configs 选项下面的 ollama_llm 部分。
如果你的 Ollama 运行在本地 (意思是与我们项目跑在同一台电脑上),base_url 不用改。
模型,也就是 model 选项,请把右侧值改成 qwen2.5:latest (对,预设选项就是这个)。
如果你希望使用其他模型,可以按照上面的流程在 ollama 中下载其他模型,用 ollama list 找到模型的完整名称,然后复制粘贴到 model 选项中。中文输入法用户常常会使用错误的全新标点符号 (比如,: 和 : 是不一样的符号) 导致错误,所以我推荐复制粘贴,避免这种错误。
如果你好奇那个 temperature 选项是什么,简单来说,temperature 越高,LLM 说的话随机性就越高。可以上网搜搜,深入了解。
运行
这个命令可以运行项目后端。
uv run run_server.py
然后项目后端就启动啦!可以在浏览器访问 localhost:12393 来打开网页。
以后记得都用这个命令来运行这个项目捏。
第一次运行会下载一些模型。目前开发版本的有些模型以及一些预设选项,发布之前会修改掉。
如果你比起浏览器中的网页,更喜欢本地应用,或是你想要背景透明能在桌面上拖来拖去的桌宠 (又或是你在网页端遇到了奇奇怪怪的问题...),可以前往 Open-LLM-VTuber-Web Release 下载并安装已经构建好的 electron 前端应用。在后端启动之后,启动你在这边下载的东西就行了。
如果你希望使用最新�版本的前端,或是你希望对前端页面做一些修改,可以参考 前端安装部署指南