Web 模式
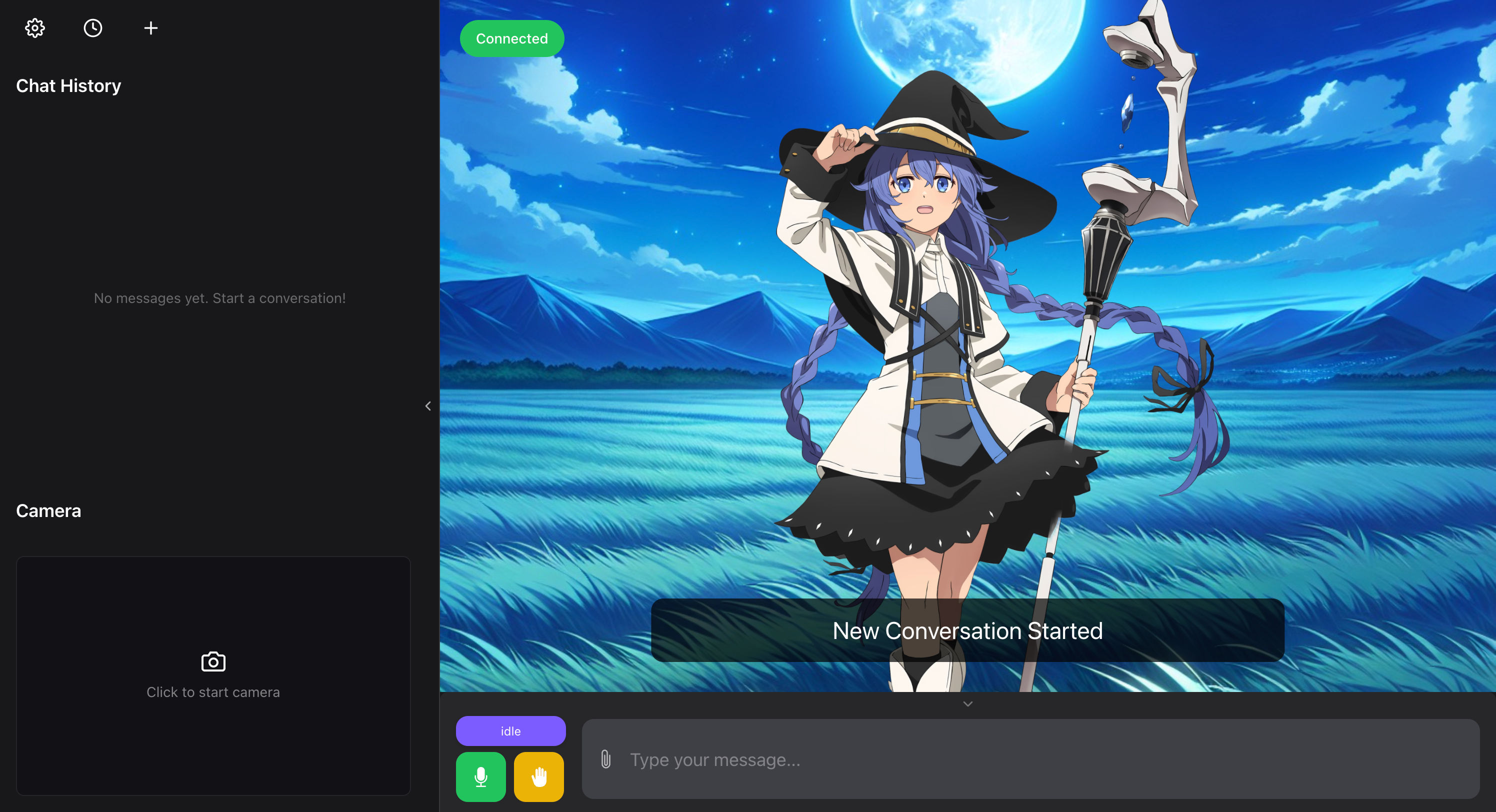
布局概览
- 侧边栏 (可折叠)
- 设置按钮
- 设置抽屉
- General
- Live2D
- ASR
- TTS
- Agent
- About
- 设置抽屉
- 对话记录
- 历史聊天抽屉
- 新建对话按钮
- 聊天记录区域
- 摄像头区域
- 设置按钮
- 主界面
- Live2D 模型 (可移动/调节大小)
- 背景图片 / 摄像头背景 (可设置)
- WebSocket 连接状态指示器 / 重连按钮
- 字幕 (可隐藏)
- 底部控制栏 (可折叠)
- 状态指示器
- 麦克风开关
- 打断按钮
- 输入框
设置概览
特性
所有设置都支持保存前预览 (TODO)。
个性化设置使用 localStorage 在本��地存储。
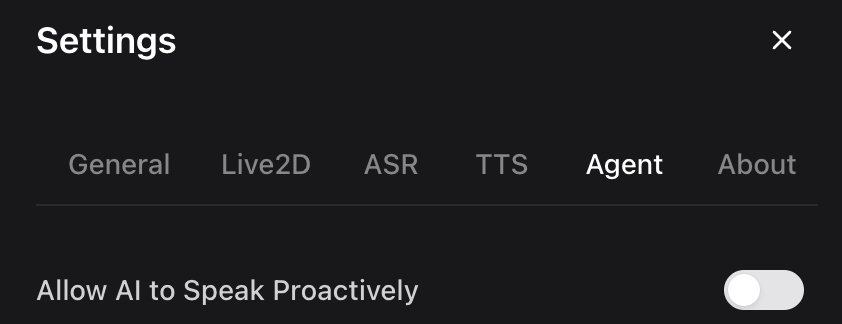
General (通用)
- 语言设置 (TODO)
- English
- 中文
- 背景设置
- 预设背景图片
- 自定义背景图片 URL
- 是否开启摄像头背景
- 角色预设选择
- WebSocket 连接地址设置
- 基础 URL 设置
- 字幕显示开关
- 恢复默认设置 (TODO)
Live2D
- 鼠标交互开关
- 开启后支持鼠标点击触发动作 (TODO)
- 开启后支持视线跟随鼠标
- 缩放开关
- 开启后可通过鼠标滚轮/双指缩放调节模型大小
ASR (语音识别)
- 自动麦克风控制
- AI 开始说话时自动关闭麦克风
- AI 被打断后自动开启麦克风
- 语音检测阈值设置
- 语音检测阈值 (Speech Prob. Threshold)
- 范围:
1-100 - 用于判断是否检测到语音的概率阈值
- 值越大,需要越清晰的语音才会被判定为说话
- 范围:
- 负语音检测阈值 (Negative Speech Threshold)
- 范围:
0-100 - 用于判断语音是否结束的概率阈值
- 值越小,越容易判定为语��音结束
- 范围:
- 恢复帧数 (Redemption Frames)
- 范围:
1-100 - 当检测到语音结束后,需要等待多少帧才真正结束语音识别
- 值越大,语音识别结束的延迟越长,但可以避免误判
- 范围:
- 语音检测阈值 (Speech Prob. Threshold)
TTS (语音合成)
- 暂无设置项
Agent (AI 代理/智能体)
- AI 主动说话设置
- 是否允许 AI 主动说话
- 空闲多少秒后允许 AI 主动说话
功能介绍
WebSocket 连接
- 连接成功时显示绿色图标。
- 连接断开时显示红色图标并自动变为重连按钮。
- 连接地址设置
- 默认连接地址为
ws://127.0.0.1:12393/client-ws。 - 可在 Setting - General 中修改连接地址。
- 默认连接地址为
AI 状态
idle(空闲)thinkg-speaking(思考/说话)interrupted(被打断)loading(加载)listening(检测到用户说话)waiting(检测到用户输入文本)
对话交互
提供多种与角色的对话交互方式
- 语音对话
- 可以 Setting - ASR 中设置自动麦克风控制和语音检测阈值。
- 确保授予麦克风权限。
- 文字输入
- AI 主动说话 (在 Setting - Agent 中设置是否开启)
- 是否允许 AI 主动说话。
- 处于空闲状态几秒后允许 AI 主动说话。
打断功能
用于中断 AI 的当前发言。当点击打断按钮时,AI 会立即停止发言,并且聊天记录和 AI 的记忆将只保留打断前的内容。有以下几种操作会触发打断:
- 点击打断按钮
- 在 Setting - ASR 中可以设置是否在点击打断按钮后,自动打开麦克风。
- 在 AI 处于
thinking-speaking状态时说话(需要麦克风处于开启状态)。- 在 Setting - ASR 中可以设置是否在 AI 切换到
thinking-speaking的状态后自动关闭麦克风。
- 在 Setting - ASR 中可以设置是否在 AI 切换到
- 在 AI 处于
thinking-speaking状态时发送消息。
消息记录
- 可滚动查看消息记录
- 支持流式响应,实时显示 AI 回复内容
- 支持查看历史消息记录,可以加载/删除单条历史记录(存储在后端)
Live2D
- 支持拖拽移动模型位置
- 支持滚轮/双指缩放调节模型大小 (可在 Setting - General 中设置是否开启)
- 支持模型视线跟随鼠标(可在 Settings - Live2D 中设置是否开启)
- 支持鼠标点击触发动作(TODO: 可在 Setting - Live2D 中设置是否开启)
- 需要提前在后端的
model_dict.json进行配置,例如:{
"name": "shizuku-local",
"tapMotions": {
"body": {
"tap_body": 30, // 点击身体区域触发 tap_body 动作,权重为 30
"shake": 30 // 点击身体区域触发 shake 动作,权重为 30
},
"head": {
"flick_head": 40 // 点击头部区域触发 flick_head 动作,权重为 40
}
}
}- 动作名称需要和模型配置文件 (
.model.json或.model3.json) 中的动作组名对应,例如shizuku.model.json中定义了tap_body、shake、flick_head等动作组,所�以在model_dict.json中也要使用相同的名称。 - 例如
shizuku.model.json中的动作组定义:{
"motions": {
"tap_body": [
{"file": "motions/tapBody_00.mtn"},
{"file": "motions/tapBody_01.mtn"},
{"file": "motions/tapBody_02.mtn"}
],
"shake": [
{"file": "motions/shake_00.mtn"},
{"file": "motions/shake_01.mtn"},
{"file": "motions/shake_02.mtn"}
],
"flick_head": [
{"file": "motions/flickHead_00.mtn"},
{"file": "motions/flickHead_01.mtn"},
{"file": "motions/flickHead_02.mtn"}
]
}
} - 当点击模型时,会先检测点击的区域(hitTest),然后根据该区域配置的动作和权重随机触发一个动作。如果未检测到命中区域,则会将所有区域的动作合并后随机触发。权重越大的动作被触发的概率越高(目前完全由前端控制)。
- 动作名称需要和模型配置文件 (
- 需要提前在后端的
- 支持说话时根据情感/后端指令自动应用表情/动作
- 需要提前在后端进行配置
背景
- 可在 Setting - General 中选择预设的背景图片
- 可在 Setting - General 中输入图片 URL 作为背景
- 摄像头实时画面
- 可在 Setting - General 中开启摄像头作为背景
- 需要授予摄像头权限
UI 折叠与隐藏
- 侧边栏可以通过点击右侧中央按钮折叠/展开
- 底部控制栏可以通过点击底部中央按钮折叠/展开
- 字幕显示可在 Setting - General 中开启/关闭
- WebSocket连接状态显示可以 Setting - General 中开启/关闭 (TODO)